Appendix A
The inclusion and
exclusion criteria.
Table 3: Inclusion
Criteria
|
Criteria |
Inclusion Criteria |
|
IC 1 |
Research articles and Conference Papers |
|
IC 2 |
Studies that address Machine Learning Operations (MLOps) in general |
|
IC 3 |
Studies that identify challenges associated with MLOps |
|
IC 4 |
Studies that included AIOps challenges |
|
Criteria |
Exclusion Criteria |
|
EC 1 |
The study that was not published in English |
|
EC 2 |
Studies that talk about the building and application of ML models |
|
EC 3 |
Studies that do not allow access to its content |
|
EC 4 |
Papers that did not have relevance to the research question |
Appendix B
The protocol for
the systematic literature review.
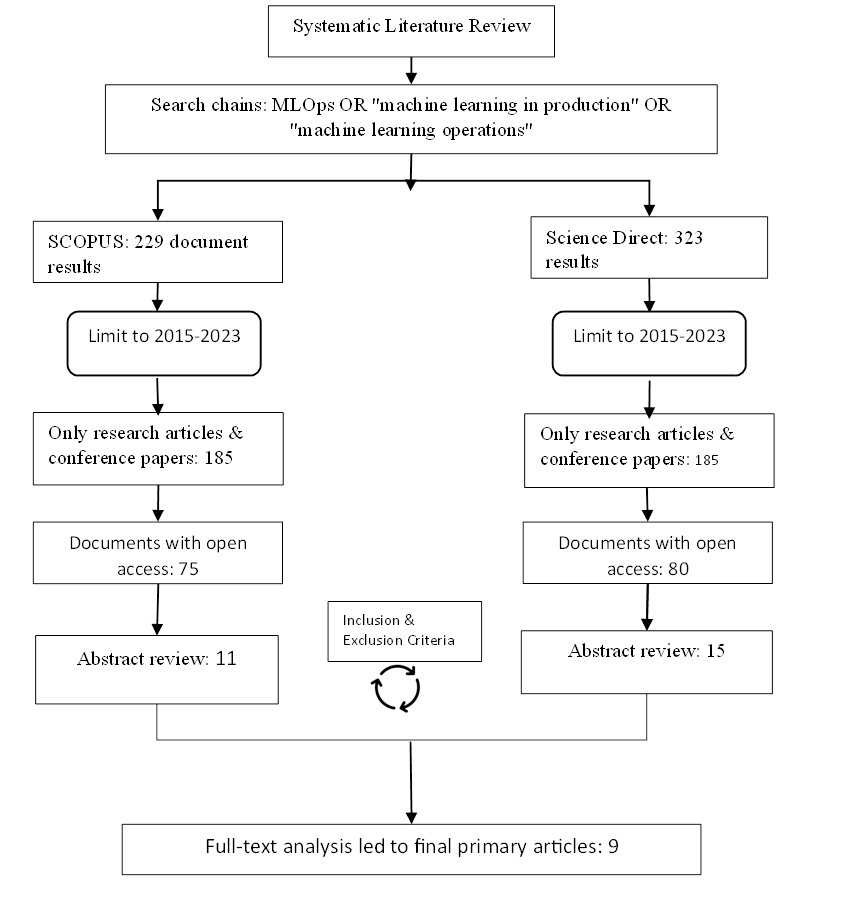
Figure 2:
Systematic literature review protocol.
Appendix C
Table 5: Participant Profile
|
Participant |
Participant Job title |
ML Experience (Years) |
Country |
Domain |
|
1 |
MLOps Lead Engineer |
9 |
Netherlands |
Publishing |
|
2 |
ML and DS Manager |
6 |
India |
Tech |
|
3 |
VP of Data Science |
9 |
India |
EdTech |
|
4 |
AI and ML Manager |
4 |
Norway |
Software provider |
|
5 |
ML team Manager |
7 |
Denmark |
Software provider |
|
6 |
Data Scientist |
4 |
Netherlands |
Software provider |
|
7 |
ML Engineer |
4,5 |
Netherlands |
Consulting |
|
8 |
Data Scientist |
9 |
Netherlands |
Bank |
|
9 |
Machine learning consultant |
5 |
Netherlands |
Consulting |
|
10 |
Product Owner for ML |
3 |
Netherlands |
Insurance |
|
11 |
MLOps Engineer |
2 |
Netherlands |
Insurance |
|
12 |
AI architect |
4 |
Netherlands |
Startup |
Appendix D
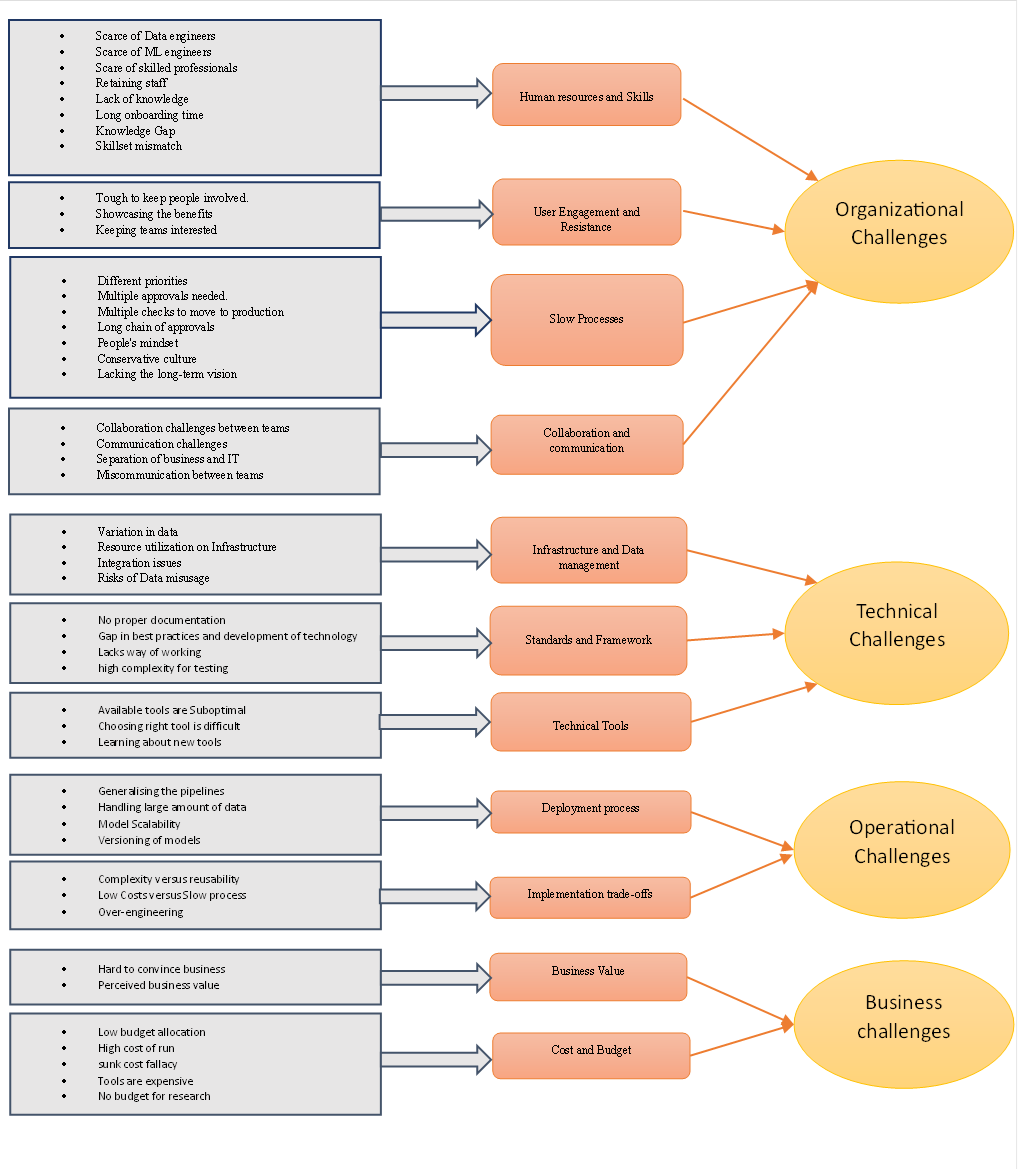
Figure 3: The
Coding Schema (grey boxes represent first level codes, the orange boxes
represent the second level codes and the yellow ovals on the right represent
the third level codes).
Appendix E
Additional Findings
During the interview,
there were some additional findings that do not directly answer the research
question but can be useful for researchers and managers looking for MLOps practices.
Prerequisites
to MLOps implementation: Most of the participants spoke about when MLOps is needed for an organization and what should be the
prerequisites to consider. Firstly, there should be a strong business
case to build ML models, and the organization should have enough clean and
valid data. As Participant 3 described, ‘I'm a strong believer in keeping
things simple and not complicated because of the buzzword of big data and ML
and AI. Literally, everyone wants to use AI, but, just
an Excel with some VBA and macros are enough sometimes.’
Secondly, the need
for MLOps comes only when there is already a manual
deployment happening. If there is only one person working on a Proof of concept
with ML, there is no need for MLOps yet. “At what
level of maturity you are in that needs to be factored in for each project, if
you are in the very early stage, implementing ML OPS doesn't really make any
sense,” says Participant 2. Lastly, the frequency at which the model needs
to be deployed into production should be considered. If the model needs to be
updated often and the frequency can be as low as a day or at least a week, then
MLOps is needed. “If it is anywhere once or twice
in a year, then you really don't need to maintain all these things” -
Participant 4
Benefits
after implementing MLOps: Organisations may face challenges
while implementing MLOps, but after implementing,
they also reap its benefits. Some of the participants shared the benefits that
they could measure. Firstly, the cost aspect is shared by multiple
participants. Before implementing MLOps, every team
had to build things from scratch, which added to more costs; after implementing
MLOps, “80% of the work is already done, teams
should just make insurance specific changes”-Participant 7.
“Price has been reduced a lot, we had lots of LSTM models in the
production for the CRF tagging, and for a single LSTM model, our project cost
was around €4221.00 for Sage Maker. After MLOps, we
are now hosting that model on our own system. And we are spending €750 per
year.”- Participant 1
Secondly, They see increased cycle time to production
and a reduction in latency. For one of the participants, the latency was around
35 seconds, and after implementing MLOps, it reduced
it to 700 milliseconds. It made it easier to trigger a pipeline to train the
model, put the model in artefact feeds, and with a click, put it in production
or to do deploying it for testing or acceptance.